- Published on
The Day I Realized I Was a Noob Coder: Lessons from an Anagram Mistake
- Authors

- Name
- Kagema Njoroge
- @reecejames934
Every coder has their moments of enlightenment and humility, and I had mine on a day when I thought I had it all figured out. It all started with a seemingly simple programming problem - checking if two strings were anagrams. Little did I know that this challenge would reveal just how much I had to learn.
The Problem That Fooled Me
The problem was straightforward: Given two strings, s and t, determine if t is an anagram of s. An anagram, as we all know, is a word or phrase formed by rearranging the letters of another word or phrase, typically using all the original letters exactly once. Piece of cake, right?
Here's the question in its entirety:
'''
Given two strings s and t, return true if t is an anagram of s, and false otherwise.
An Anagram is a word or phrase formed by rearranging the letters of a different word or phrase, typically using all the original letters exactly once.
Example 1:
Input: s = "anagram", t = "nagaram"
Output: true
Example 2:
Input: s = "rat", t = "car"
Output: false
Constraints:
1 <= s.length, t.length <= 5 * 104
s and t consist of lowercase English letters.
'''
My Initial Solution - A Dose of Overconfidence
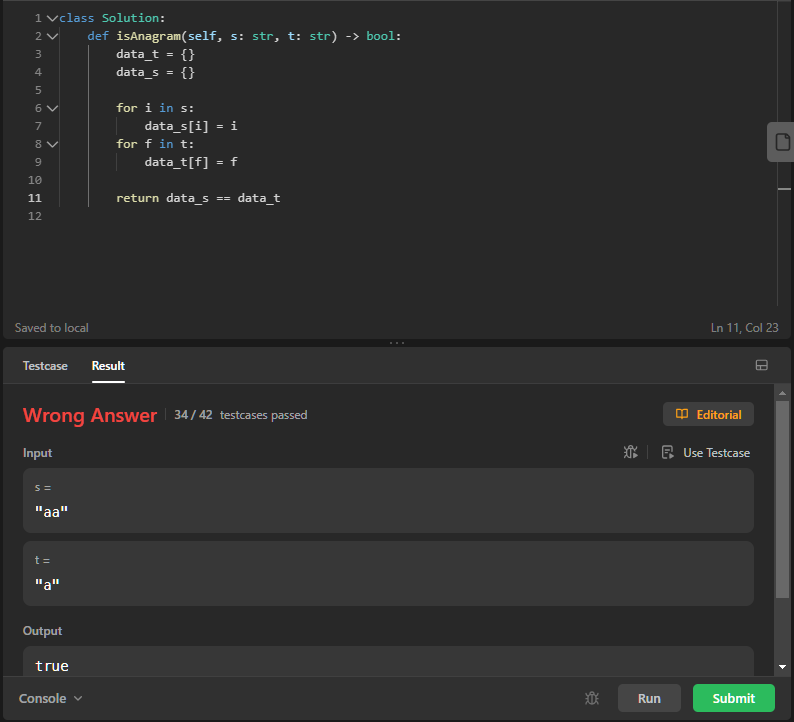
I dived into the problem headfirst, convinced that I could conquer it effortlessly. My initial solution? Compare the two strings character by character and return True if they were the same length. Simple enough, or so I thought:
def anagram(s: str, t: str) -> bool:
if len(s) != len(t):
return False
data_t = {}
data_s = {}
for i in s:
data_s[i] = i
for f in t:
data_t[f] = f
return data_s == data_t
The "Aha! 😒" Moment
I ran my code, and it seemed to work for some test cases. I felt a momentary sense of accomplishment. But then reality hit me like a ton of bricks. What about the characters' counts? An anagram isn't just about having the same characters; it's about having the same characters in the same quantities.
The Big Mistake
My "brilliant" solution had completely overlooked this crucial aspect. I realized that my code would incorrectly declare strings like "rat" and "car" as anagrams simply because they contained the same characters.
Learning from Humility
This experience was a humbling reminder that in coding, as in life, overconfidence can lead to mistakes. I had rushed into solving the problem without fully understanding its requirements. But there's no shame in making mistakes; the real shame is not learning from them.
The Revised Solution
I knew I had to fix my code. I learned about the importance of character counts in anagrams and came up with a revised solution that properly addressed this aspect.
def anagram(s: str, t: str) -> bool:
if len(s) != len(t):
return False
char_count = {}
for char in s:
if char in char_count:
char_count[char] += 1
else:
char_count[char] = 1
for char in t:
if char in char_count:
char_count[char] -= 1
if char_count[char] < 0:
return False
else:
return False
return True
Conclusion
My journey from overconfidence to humility taught me a valuable lesson in coding: never underestimate the importance of understanding the problem fully. Anagrams aren't just about matching characters; they're about matching character counts. I may have started as a "noob" coder, but I'm determined to keep learning and growing, one mistake at a time.
The link to the original problem can be found here.
In the world of coding, no one is immune to "noob" moments, and that's perfectly okay. It's these moments that make us better programmers in the long run. So, here's to embracing our mistakes, learning from them, and becoming better coders every day! 🚀👩💻💡