- Published on
Character vs. Word Tokenization in NLP: Unveiling the Trade-Offs in Model Size, Parameters, and Compute
- Authors

- Name
- Kagema Njoroge
- @reecejames934
In Natural Language Processing, the choice of tokenization method can make or break a model. Join me on a journey to understand the profound impact of character-level, word-level tokenization and Sub-word tokenization on model size, number of parameters, and computational complexity.
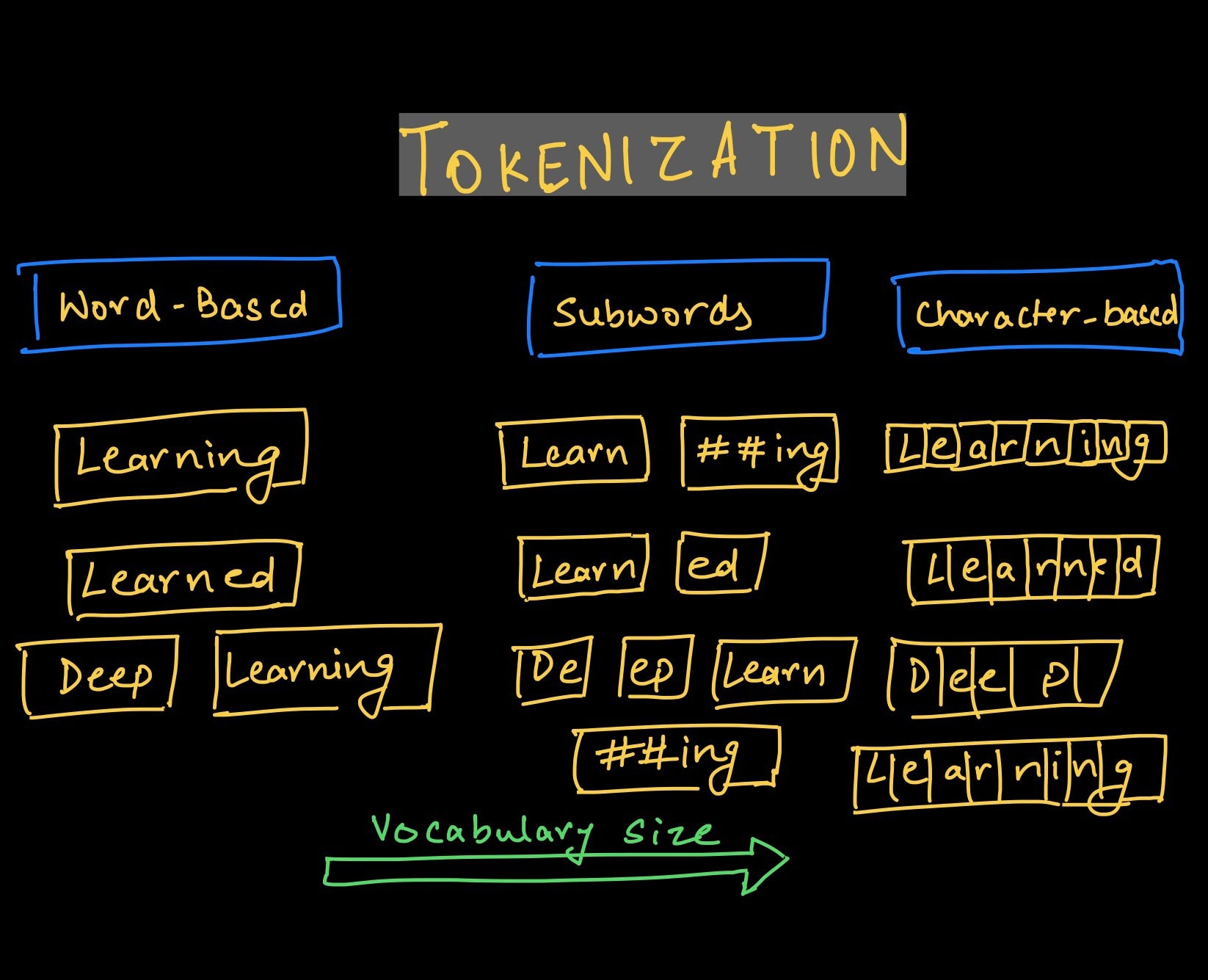
First Things First, What is Tokenization?
AI operates with numbers, and for deep learning on text, we convert that text into numerical data. Tokenization breaks down textual data into smaller units, or tokens, like words or characters, which can be represented numerically.
Decoding Tokenization
There are various techniques in tokenization, such as:
- Word Tokenization: Divides text into words, creating a vocabulary of unique terms.
- Character Tokenization: Breaks down text into individual characters, useful for specific tasks like morphological analysis.
- Subword Tokenization: Splits words into smaller units, capturing morphological information effectively. Examples BERT and SentencePiece
Character-Level Tokenization
We essentially create tokens out of individual characters present in the text. This involves compiling a unique set of characters found in the dataset, ranging from alphanumeric characters to ASCII symbols. By breaking down the text into these elemental units, we generate a concise set of tokens, resulting in a smaller number of model parameters. This lean approach is particularly advantageous in scenarios with limited datasets, such as low-resource languages, where it can efficiently capture patterns without overwhelming the model.
# Consider the sentence, "I love Python"
# If we tokenize by characters the result will be ['I', ' ', 'l', 'o', 'v', 'e', ' ', 'P', 'y', 't', 'h', 'n']
sent = "I love Python"
tokens = [i for i in set(sent)] # Use a set to obtain ony unique ones
# if we then represent the sentence above numerically
numerical_representation = {i:ch for i, ch in enumerate(tokens)}
number_of_tokens = len(s)
Word-Level Tokenization:
Word-level tokenization involves breaking down the text into individual words. This process results in a vocabulary composed of unique terms present in the dataset. Unlike character-level tokenization, which deals with individual characters, word-level tokenization operates at a higher linguistic level, capturing the meaning and context of words within the text.
This approach leads to a larger model vocabulary, encompassing the diversity of words used in the dataset. While this richness is beneficial for understanding the semantics of the language, it introduces challenges, particularly when working with extensive datasets. The increased vocabulary size translates to a higher number of model parameters, necessitating careful management to prevent overfitting.
# Consider the sentence, "I love Python"
sent = "I love Python"
tokens = [i for i in set(sent.split())]
numerical_representation = {i:ch for i, ch in enumerate(tokens)}
However, the trade-off lies in the potential for overfitting, especially when dealing with smaller datasets. Striking a balance between a rich vocabulary and avoiding over-parameterization becomes a critical consideration when employing word-level tokenization in natural language processing tasks.
Subword Tokenization
Subword tokenization interpolates between word-based and character-based tokenization.
Instead of treating each whole word as a single building block, subword tokenization breaks down words into smaller, meaningful pieces. These smaller parts, or subwords, carry meaning on their own and help the computer understand the structure of the word in a more detailed way. Common words get a slot in the vocabulary, but the tokenizer can fall back to word pieces and individual characters for unknown words.
Let's do a simple experiment to show the impacts of a tokenization method on the model
Colab Link to the code

From the experiment I conducted above the trend is as follows:
- As the number of tokens increases:
- The model size also increases
- Model training and inference becomes more compute demanding
- The size of dataset required to achieve high accuracy also increases
Which tokenization method should I use?
Sub-word tokenization is the industry standard!
Consider Byte Pair Encodinge(BPE) techniques such as:
Use character level tokenization or word level tokenization where you have a smaller dataset.